

Автонаполняемый сайт — вебресурс, который автоматически наполняется за счет контента с других сайтов. В целом автонаполнение сайта чужим контентом — это неправильно, но если несколько отодвинуть в сторону вопросы морали и авторского права, то остается большой сегмент контента, который можно копировать без больших угроз получить по голове: анонсы, новости, пресс-релизы.
На основе таких автонаполняемых новостей можно сделать как весь сайт целиком, так и отдельный раздел на существующем сайте. Например на сайте, посвященному боксу, сделать раздел спортивных новостей. А на сайте про актеров — новости из мира кино. За счет публикаций новостей можно попробовать ловить ситуативный трафик, с этих страниц можно торговать ссылками, с них можно проставлять перелинковку на свои продвигаемые страницы.
Пример из практики: Новостной сайт с автопубликацией 5-10 материалов в день, несколько раз за зиму выходил в топ по запросам связанными с отменой занятий в школах из-за мороза.
Как сделать автонаполняемый вордпресс-сайт с плагином wp-grabber
Для создания автонаполняемого проекта на понадобится готовый установленный сайт на вордпресс, сам плагин, настройка лент и немного терпения, потому как придется повозиться (потанцевать с бубном).
Вопрос — где взять плагин wp-grabber
Это плагин-граббер (парсер новостей), основанный на принципе копирования материала по признакам. Он используется с 2009 года и уже больше тысячи пользователей используют его на своих сайтах. К тому же наличие общего формата файлов экспорта/импорта позволяют без проблем пользоваться настроенными лентами в обоих этих приложениях. Почему именно WPGrabber: Он импортирует контент с любого HTML-сайта, RSS-потока, со стен групп и сообществ ВК. Благодаря гибким настройкам обработки автоматически удаляются ненужные блоки информации, ссылки и картинки. Поддерживает режим автоматической работы обновления с другими сайтами. Работает без ограничений – собирает тексты с любого количества сайтов.
Тут есть несколько вариантов:
- купить доступ к плагину у разработчиков (поищите в гугле по запросу вп-граббер) — удовольствие примерно 250-500 рублей.
- Зайдите на сайт складчин — и скачайте его там (снова гугл в помощь).
- Можно попробовать скачать одну из таких версий здесь.
Как установить и настроить
Плагина нет в официальном репозитории, поэтому устанавливаем плагин через загрузку архива (панель управления — плагины — добавить новый — загрузить).

Далее активируете плагин и переходите в раздел раздел настроек.
И в настройках нужно будет только включить обновление через CRON.

Остальные настройки можно не трогать. Самое важное — правильно настроить ленты для граббинга и отображение публикаций на сайте.
Ниже представлены стандартные настройки для плагина WPGrabber
Теперь пройдемся по пунктам:
- Для запросов использовать метод -> CURL (основная функция для парсинга контента)
- Для скачивания файлов (картинок) использовать метод -> COPY (основная функция для грабинга и сохранения изображений)
- Включить обработку редиректов -> Да
- Максимальное время ожидания ответа от сервера -> 30 (вполне достаточно 30, пустое значение будет заменено на параметр из настроек вашего хостинга, сервера)
- Каталог временных файлов -> /wp-content/wpgrabber_tmp/
- Время выполнение основного процесса импорта в секундах -> 30 (вполне достаточно 30, пустое значение — по умолчанию: 30 сек.)
- Разбивать процесс импорта на части -> Да
- Сохраняем изменения
Как настроить ленты для граббинга
Это самая сложная часть, поэтому разберем ее подробнее. Бояться ошибиться не надо, если лента не заработала — просто возьмите другую. Наберитесь терпения и начнем.
Есть простой и платный путь: вы подбираете источники и обращаетесь к разработчикам или фрилансерам на Кворк — они сделают вам первые ленты из расчета примерно 5 лент за 500 рублей.
Итак, идем в настройки вп-грабера и жмем добавить новую ленту — и видим несколько закладок. На будут нужны:
- Основные — это главные настройки получения контента.
- Контент — там выберем рубрики и схему публикации
- Картинки — записи с изображениями дают больше ПФ (поведенческих факторов)
- Вид — здесь пропишем шаблон поста

Основные настройки — именно на них нужно обратить пристальное внимание.

- Наименование ленты — тут пишем чтобы вам было понятно или удобно, можно вставить просто урл сайта;
- Тип ленты — самые полные варианты удается спарсить при выборе html;
- Индексная страница — тут все понятно — пишем урл сайта;
- Кодировка страницы — смотрим кодировку, чаще встречается utf-8 и windows-1251. Для этого открываем код страницы ( в гугл хром, мозила файервокс и интернет эксплорер — это быстрые клавиши ctrl+u) — пример на картинке ниже;
- Определять анонс — на ваше усмотрение, рекомендую оставить «автоматически»;
- Самые главные пункты основной настройки — уделим им внимание несколько ниже: подробно разберем на примере какого-нибудь сайта;
- Ленту — включить.
Для того чтобы посмотреть исходный код (HTML-код страницы) можно также просто щелкнуть в любом месте по странице правой кнопкой мыши и в контекстном меню выбрать Просмотр кода страницы.
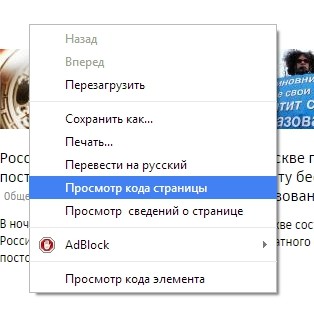
Еще раз обратите внимание на то, как в исходном html-коде страницы указывается кодировка:
<meta http-equiv=»Content-Type» content=»text/html; charset=ЗДЕСЬ КОДИРОВКА» />
На некоторых сайтах кодировка не указана, тогда пробуйте значение: Исходная, или же WINDOWS-1251.
Подробней рассмотрим пункт 6 — Расписываем шаблоны ссылок, заголовка, стартовой и конечной точки контента.
Для начала разберем структуру ссылок, они бывают разные — в зависимости от CMS донора. Самые простые ссылки выглядят примерно так домен/слово, например http://seodelux.ru/portfolio
Какие могут быть варианты:
- домен/слово
- домен /слово
- домен/цифры
- домен/набор цифр и букв
- домен/набор сложных символов
- и более сложные композиции, сочетающие все варианты
Вариантов может быть много, тут важно умение мыслить логично, анализировать структуру ссылок. Приходит такое умение с опытом, так что практикуйтесь и задайте вопросы в комментах, если что не понятно.
Особое внимание обратите на правильное обозначение регулярных выражений.
Подбор шаблона ссылок
Рассмотрим на примере добавления одной ленты. Возьмем сайт новостей шоу-бизнеса starhit.ru
Первое что нужно понять — как выглядит ссылка в структуре сайта. Для этогоо идем на индексную страницу — смотрим ее код (ctrl+U) и через поиск по странице (ctrl+F) ишем заголовок и ссылку. Я просто начинаю искать в исходном коде через поиск начало заголовка. Смотрите на картинке выше.
У нас она получилась такого вида: /novosti/nastasya-samburskaya-ofitsialno-vyishla-zamuj-134191/
Так и будем вставлять ее в вп-граббер. Теперь нам необходимо заменить конкретный адрес на шаблон. Анализируем структуру: /раздел/несколько-слов-через-дефис-цифры. Проверим себя — посмотрим как выглядят другие ссылки. В нашем примере структура определена верно:

Посморим также другие разделы:
- /style/kak-izbavit-rebenka-ot-internet-zavisimosti-134016/
- /life/moe-telo-tyurma-kogda-pogonya-za-idealnyim-vesom-prevraschaetsya-v-bolezn-118797/
- /photoistorii/anita-tsoy-vnov-brosila-vyizov-shou-biznesu-134162/
- /eksklusiv/svadba-nikityi-presnyakova-i-alenyi-krasnovoy-eksklyuziv-foto-video-131883/
Пробуйте — не бойтесь ошибиться, не получилось — возьмите другой сайт-донорУбеждаемся, что схема верна. Теперь нам нужно задать шаблон ссылок в регулярных выражениях.
В регулярных выражениях PCRE любой непробельный символ обозначается следующей конструкцией \S
Обратите внимание на слэш \ перед заглавной буквой S. Обратный слэш в регулярных выражениях отменяет обычное действие символа, мы могли бы написать просто символ буквы S и тогда она была бы просто заглавной буквой S в нашем регулярном выражении. Однако \S — означает ровным образом один любой символ, кроме пробела!
Погуглите в интернете о регулярных выражениях PCRE — для общего образования.
Теперь попробуем указать количество символов в строке. количество символов задается такими регулярными выражениями:
- \S{5} — пять любых смиволов
- \S{9} — девять любых символов
- \S{3,7} — от трех до 7 символов включительно.
И если с разделами еще можно угадать, просто посчитав число символов — новости (7 символов), стайл (5 символов), то вот с остальной частью ссылки — угадать сложно. Решение простое — нужно указать что число символов — больше 1. Выгдялеть регулярное выражение будет таким образом — \S{1,}
Можно и уточнить — в разделах у нас указаны только буквы, а одна буква в системе PCRE имеет обознаяение \w
Попробуем вставить в шаблон ссылок сдедующее выражение
/\w{1,} /\S{1,}/
В тесте получаем ссылки рабочие, но ненужные — на служебные страницы, например:
- http://www.starhit.ru/js/wam/customers/
- http://www.starhit.ru/contacts/
Меняем вторую часть шаблона. Буквы в регулярных выражениях обозначаются \w, а цифры — \d. Во второй части шаблона имеются и буквы и цифры, поэтому регулярное выражение мы можем задать как \w\d
Когда нам нужно в регулярном выражении перечислить вхождение разных символов (набора символов), то мы можем использовать квадратные скобки. Выражение получается вида:
[\w\d]{1,}
Это означает: любая одна буква или одна цифра или более подобных символов.
Нам также нужно отсечь в первой части ненужные разделы, изменим там условие — минимальное число букв-5. Теперь давайте протестируем суммарно получившийся шаблон
/\w{5,}/[\w\d]{1,}
Результат видим такой:

Значит шаблон ссылок правильный и теперь можно продолжать настройку. Еще раз напомню, что работа с регулярными выражаениями для простого вебмастера и блогера — наиболее сложный этап. Запомните основные переменные которые нам понадобятся:
\S \d \w плюс квадратные и фигурные скобки
Подбор шаблона заголовка
Для того чтобы WPGrabber нашел заголовок в тексте страницы определенной новости нам необходимо описать шаблон его поиска. Тут тоже используется формат регулярных выражений как и в описании шаблона ссылок.
Идем на страницу новости и смотрим еще раз ее исходный html-код. Копируем заголовок и с помощью ctrl+F ищем его на странице. Среди многообразия нам нужно найти наиболее подходящий вариант — без дополнительных слов и символов.
В нашем случае мы видим варианты:
- <title>Настасья Самбурская официально вышла замуж | StarHit.ru</title>
- <meta property=»og:title» content=»Настасья Самбурская официально вышла замуж | StarHit.ru«>
- <meta name=»twitter:title» content=»Настасья Самбурская официально вышла замуж«>
- <h1 xmlns=»http://www.w3.org/1999/xhtml» class=»article-title» itemprop=»name«>Настасья Самбурская официально вышла замуж </h1>
- Вот именно в этом примере я бы испольховал третий. Составляем шаблон, который будет состоять из трех частей: <meta name=»twitter:title» content=»НАЗВАНИЕ«>
Тут нужно запомнить два правила:
- Круглые скобки обозначают выборку определенной части текста из строки <meta name=»twitter:title» content=»(НАЗВАНИЕ)»>
- Конструкция вида: .*? вбирает (поглощает) в себя любое кол-во символов вплоть до встречи со следующим символом после нее.
Итого заменяем НАЗВАНИЕ в шаблоне на (.*?) и получаем следующую рабочую структуру, которую и протестируем:
<meta name=»twitter:title» content=»(.*?)»>
WPGrabber теперь находит правильные заголовки:

<meta name=»title» content=»(.*?)» />
<title>(.*?)</title>
<h1>(.*?)<h1/>
Настройка начальной точки и конечной точки контента
Снова переходим на нашу страницу новости с исходным кодом и ишем начало текста и конец. Для этого снова можно воспользоваться поиском ctrl+F. Смотрим метатег, который есть перед началом текста и вставляем его в настройках плагина.

В нашем случае можно пробовать два варианта, я бы использовал то, который выделен красным цветом — метатег явно указывает на начало текстового контента: <div class=»article-body«>
Теперь смотрим метатег после текста статьи. В нашем случае подойдет тег <div class=»article-side«>.

Тестируем и смотрим на результат: шаблон ссылки сработал, заголовок — корректный, есть текстовый и даже фото-контент.

Все первая и наиболее важная часть подготовки сделана.